Moonshot AI and Tsinghua Researchers Propose PrfaaS: A Cross-Datacenter KVCache Architecture that Rethinks How LLMs are Served at Scale


For years, the way large language models handle inference has been stuck inside a box — literally. The high-bandwidth RDMA networks that make modern LLM serving work have confined both prefill and decode to the same datacenter, sometimes even the same rack. A team of researchers at Moonshot AI and Tsinghua University is making the case that this constraint is about to break down — and that the right architecture can already exploit that shift.
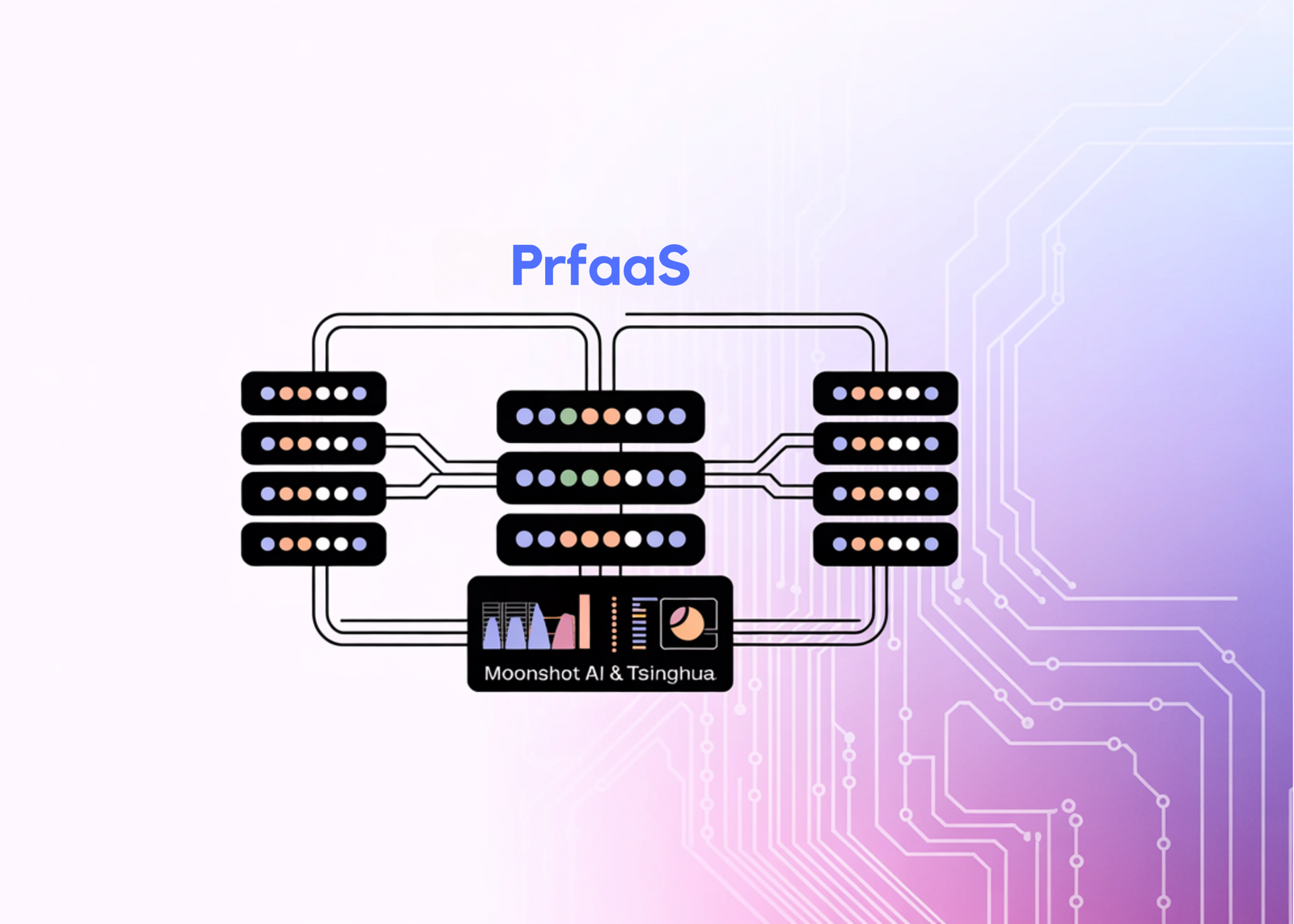
The research team introduces Prefill-as-a-Service (PrfaaS), a cross-datacenter serving architecture that selectively offloads long-context prefill to standalone, compute-dense prefill clusters and transfers the resulting KVCache over commodity Ethernet to local PD clusters for decode. The result, in a case study using an internal 1T-parameter hybrid model, is 54% higher serving throughput than a homogeneous PD baseline and 32% higher than a naive heterogeneous setup — while consuming only a fraction of available cross-datacenter bandwidth. The research team note that when compared at equal hardware cost, the throughput gain is approximately 15%, reflecting that the full 54% advantage comes partly from pairing higher-compute H200 GPUs for prefill with H20 GPUs for decode.

Why the Existing Architecture Has Hit a Wall
To understand what PrfaaS solves, it helps to understand why LLM serving is split into two phases in the first place. Prefill is the step where the model processes all of the input tokens and generates the KVCache — it is compute-intensive. Decode is where the model generates output tokens one at a time — it is memory-bandwidth-intensive. Prefill-decode (PD) disaggregation separates these two phases onto different hardware, which improves utilization and allows each phase to be independently optimized.
The problem is that separating prefill from decode creates a transport problem. Once prefill runs on one set of machines and decode runs on another, the KVCache produced by prefill must be transferred to the decode side before output generation can begin. In conventional dense-attention models — those using Grouped Query Attention (GQA) — this KVCache is enormous. The research team benchmarks MiniMax-M2.5, a representative dense model with GQA, producing KVCache at roughly 60 Gbps for a 32K-token request on a single 8×H200 instance. That volume of data requires RDMA-class interconnects to transfer without stalling compute, which is why conventional PD disaggregation is tightly bound to a single datacenter-scale network fabric. Moving prefill and decode to separate clusters, let alone across datacenters, has simply not been feasible.
Hybrid Attention Changes the Math
What makes PrfaaS timely is an architectural shift happening at the model level. A growing class of models — including Kimi Linear, MiMo-V2-Flash, Qwen3.5-397B, and Ring-2.5-1T — adopt hybrid attention stacks that interleave a small number of full-attention layers with a larger number of linear-complexity or bounded-state layers such as Kimi Delta Attention (KDA), Multi-head Latent Attention (MLA), and Sliding Window Attention (SWA). In these architectures, only the full-attention layers produce KVCache that scales with sequence length. The linear-complexity layers maintain fixed-size recurrent states whose footprint is negligible at long context.
The KV throughput numbers — defined as KVCache size divided by prefill latency — tell the story clearly. At 32K tokens, MiMo-V2-Flash produces KVCache at 4.66 Gbps versus 59.93 Gbps for MiniMax-M2.5, a 13× reduction. Qwen3.5-397B reaches 8.25 Gbps versus 33.35 Gbps for Qwen3-235B, a 4× reduction. For Ring-2.5-1T specifically, the paper decomposes the savings: MLA contributes roughly a 4.5× compression over GQA, and the 7:1 hybrid ratio contributes another approximately 8× reduction, yielding an overall KV memory saving of roughly 36×. For the internal 1T model used in the case study, KV throughput at 32K tokens is just 3.19 Gbps — a level that modern inter-datacenter Ethernet links can actually sustain.
But the research team is careful to make a distinction that matters for AI devs building real systems: a smaller KVCache is necessary but not sufficient to make cross-datacenter PD disaggregation practical. Real workloads are bursty, request lengths are skewed, prefix caches are distributed unevenly across nodes, and inter-cluster bandwidth fluctuates. A naive design that routes every prefill to a remote cluster still runs into congestion and unstable queuing.

What PrfaaS Actually Does
The PrfaaS-PD architecture sits on top of three subsystems: compute, network, and storage. The compute subsystem separates clusters into two types — local PD clusters that handle end-to-end inference for short requests, and PrfaaS clusters with high-compute-throughput accelerators dedicated to long-context prefill. The network subsystem uses intra-cluster RDMA for fast local transfers and commodity Ethernet for cross-cluster KVCache transport. The storage subsystem builds a distributed hybrid prefix cache pool that handles linear attention recurrent states (request-level, fixed-size, exact-match only) and full-attention KVCache blocks (block-level, growing linearly with input length, supporting partial prefix matching) in separate groups backed by a unified block pool.
The key routing mechanism is length-based threshold routing. Let l denote the incremental prefill length of a request after subtracting any cached prefix, and t a routing threshold. If l > t, the request goes to the PrfaaS cluster and its KVCache is shipped over Ethernet to a decode node. If l ≤ t, it stays on the local PD path. In the case study, the optimal threshold is t = 19.4K tokens, which routes approximately 50% of all requests — the longer ones — to the PrfaaS cluster.
Making the Ethernet path reliable in practice requires more than just low KV throughput. The research team specifies three concrete transport mechanisms: layer-wise prefill pipelining to overlap KVCache generation with transmission, multi-connection TCP transport to fully utilize available bandwidth, and congestion monitoring integrated with the scheduler to detect loss and retransmission signals early and prevent congestion accumulation.
On top of this, the research team introduces a dual-timescale scheduler. At short timescales, it monitors PrfaaS egress utilization and queue depth, adjusting routing when the link approaches its bandwidth ceiling. It also handles cache-affine routing: when bandwidth is scarce, each cluster’s prefix cache is evaluated independently; when bandwidth is abundant, the scheduler considers the best cached prefix across all clusters and performs a cross-cluster cache transfer if it reduces redundant computation. At longer timescales, the scheduler rebalances prefill and decode node counts within the local PD cluster as traffic patterns shift, keeping the system near the throughput-optimal operating point.
The Numbers
In the case study, a PrfaaS cluster of 32 H200 GPUs is paired with a local PD cluster of 64 H20 GPUs, connected by a VPC network providing approximately 100 Gbps of cross-cluster bandwidth. The aggregate PrfaaS egress load under the optimal configuration is approximately 13 Gbps — just 13% of available Ethernet capacity — and the paper notes that the PrfaaS cluster remains compute-bound with substantial bandwidth headroom to spare. The research also projects this to larger deployments: even at the scale of a 10,000-GPU datacenter, the aggregate egress bandwidth required for KVCache transfer totals only about 1.8 Tbps, well within the capacity of modern inter-datacenter links.
Mean Time to First Token (TTFT) drops by 50% and P90 TTFT drops by 64% compared to the homogeneous baseline. The naive heterogeneous configuration — all prefill on H200, all decode on H20, with no routing or scheduling logic — achieves only 1.16× throughput over the homogeneous baseline, compared to 1.54× for the full PrfaaS-PD system. The gap between 1.16× and 1.54× isolates the contribution of the scheduling layer and shows it accounts for the majority of the practical gain.
The research team positions PrfaaS not as a near-future concept but as a design that is viable today for hybrid-architecture models — and argues that as context windows grow, KVCache compression techniques mature, and phase-specialized hardware such as NVIDIA’s Rubin CPX for prefill and LPU-style chips for decode become more widely available, the case for cross-datacenter PD disaggregation will only strengthen.
Check out the Paper here. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
